Configuring the LiSA Search
Prerequisities
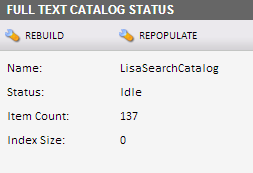
NOTE: Even though you receive an error message and the full-text catalog does not seem to be working properly, the following two steps can still be performed to get the crawler running, even though the actual search functionality will not work properly.
Step 1: Enabling the search
First you need to enable the search on your website. If you have multiple websites running in your LiSA instance, you must repeat this step for each website you want the crawler to crawl.
- Go to "System" and "Search Manager".
- Click "Crawler settings" in the tree on the left hand side.
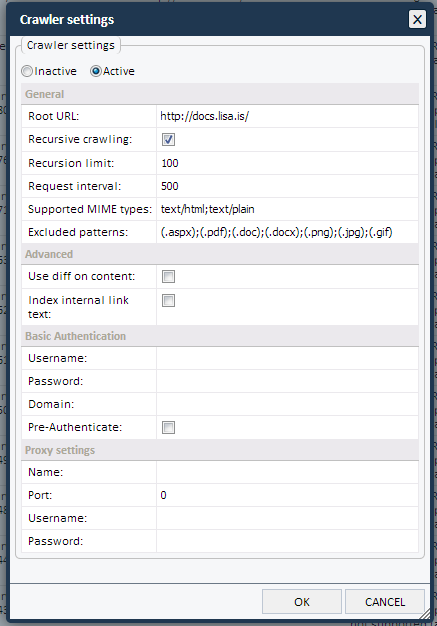
- The following dialog pops up:
- Click "Active" at the top of the dialog and the rest of the settings will be shown.
- For the most part, the default values are OK. The Root URL should have been populated automatically, if your website has a default host-header specified. If not, make sure to type in the URL of your website, including the "http://" part.
- The Recursion limit defines how deep the crawler goes when following internal links on your website. A value of 2 or 3 will suffice on most websites.
- If you are running LiSA 6.8, the crawler can index PDF and MS Word documents. To enable that, make sure that the "Supported MIME types" contains those content types as well.
- The correct value should be:"text/html;text/plain;application/pdf;application/msword;application/vnd.openxmlformats-officedocument.wordprocessingml.document" (without quotes).
- Also make sure that the "Excluded patterns" does not include .pdf, .doc and .docx. Use this for example: "(.aspx);(.png);(.jpg);(.gif)" (without quotes).
- Leave all the other settings as they are, unless you need to provide authentication information (if your website does not allow anonymous access).
- Click OK.
If your LiSA instance has other websites configured you wish to enable the search for as well, switch to the next website and repeat this step.
Step 2: Creating the crawler task
In step 1 you basically only enabled the search on your website, but that will accomplish nothing unless the actual crawler task is started as well. In this step you will create a task which runs the crawler at specified intervals to regularly crawl and index the content on your website. The crawler will load and use the settings you specified in step 1.
- Go to "System" and "Task Daemon".
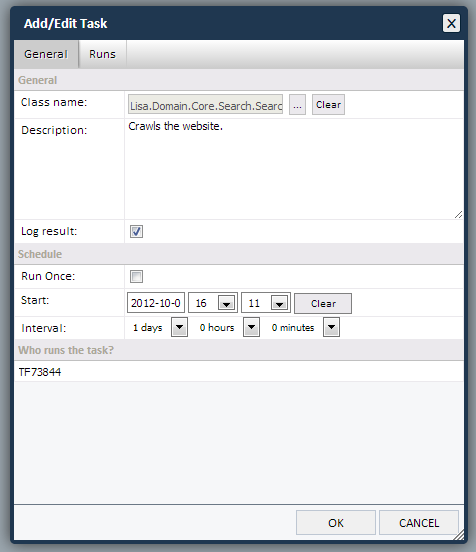
- Click "New" and the "Add new task" dialog pops up.
- Click the "..." button next to the "Class name" and select the "LisaSearchCrawler" task from the list of available tasks.
- Give the task a description, and make sure to check "Log result" so everytime this task is run, it will be logged.
- Specify when you want the task to run initially and then at which interval after that.
- Finally you need to specify who runs the task. You can type in the name of the web server or select from a list of predefined roles. For more information about the task daemon and the roles, see The LiSA Task Daemon.
- Click OK and you should be all set.
Monitoring the task
You can monitor the task by opening it from the list and switching over to the "Runs" tab. Each time the task runs, a new entry is added to the list. You can double click an entry in the list to see more information. Note that the crawler task can take a few minutes to complete, all depending on the size of your website. If there's an entry in the list with no end date, then the task is most likely still running. In that case, you can head over to "System" and "Search Manager" and click "View Search Catalog". There you can see the content which the crawler has found and indexed.